
Introduction to Apache Solr
Solr is an open-source search engine built on top of Apache Lucene. Solr was created by Yonik Seeley at CNET Networks in 2004 for their in-house project to facilitate search functionality to his company website.
For reference, Apache Lucene works based on an inverted index to store documents (data) and provides search and indexing functionality via a Java API. Thus, Solr is a much more advanced version of Lucene’s search engine. It offers more functionality and has a design optimized for scalability. Communications in Solr are done via REST clients, wget, curl, Chrome’s POSTMAN, native clients, etc. It supports both XML and JSON APIs.
How does Apache Solr work?
When we submit a query to the Solr search engine, it separates queries into different pieces/entities, then matches the query with the document’s inverted index that was created earlier. The Solr search engine returns a set of documents as a response based on the similarity in class or other characteristics defined in the schema.xml and solr.config file.
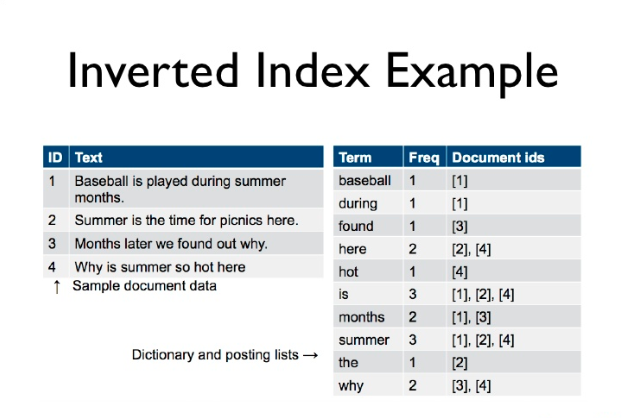
As Solr is based on Apache Lucene, Lucene stores input data as an inverted index. In an inverted index, each indexed term points to a list of documents that contain the term. It is similar to the index provided at the end of a book. Below is the example for the Inverted Index:
Features of Apache Solr:
- Apache Solr provides below essential features.
- Paginations
- Highlighting
- Sorting
- Faceted search and Filtering
- Auto-suggest
- Spell check
- Replication
- Automatic load balancing
- Batch and Streaming process
- Center configuration for the entire cluster
- Geospatial support
Advantages of Apache Solr:
- It’s fast, powerful, flexible, and simple search engine
- Comprehensive HTML-based Administration Interface
- Helps make your products and services more accessible
- Helps reduce the amount of time taken to locate information
- Increases the time customers spend on web applications
- Flexible and Adaptable with XML configuration
- Extensible Plugin Architecture
- Highly Scalable, robust, fault-tolerant search engine
- Helps you improve user experience on the web application to increase revenue and profit
- Supports Distributed, Replication, Clustering, and Multi-Node Architecture
Apache Solr’s Ecosystem:
Apache Solr has a large open-source community of well-experienced users. Anyone can contribute to Solr. New Solr developers and code committers are selected based upon merit only. Solr has a healthy project pipeline and many well-known companies that take part. Solr has been around for a much longer time, and Solr’s ecosystem is well-developed with a broader user base.
Conclusion:
Solr search engine is fast for text searching/analyzing because of its inverted index structure. Solr is consistent and very well-documented. If your application requires the sort of extensive text searching that Solr supports, then Solr is the right choice for you. There are dozens of big-name companies (like AT&T, Netflix, Verizon, and Qualcomm) that use Solr as their primary search engine. Even Amazon Cloud search, which is a search engine service by AWS, uses Solr internally.