
What is NoSQL?
NoSQL is a non-relational, “Not-only-SQL” database that provides a mechanism to store and retrieve unstructured and semi-structured data. The data is stored in a non-tabular format and mainly involves handling big data applications. NoSQL databases are highly scalable, available, flexible, and agile; they don’t use tabular relations, are large-scale distributed, massively parallel, and commodity servers. There are various flavors of NoSQL databases.
- Document Store: Data is stored as documents like JSON and XML
- Key-value: Uses a key-value pair to store data
- Columnar Store: Contains rows with varying numbers of columns and varying column names
- Graph Database: It stores and represents the data in a graphical format as nodes and relationships
NoSQL Vs. Relational Databases
Here are some differences between NoSQL and Relational databases.
Relational | NoSQL | |
Data Structure | Data is stored in predefined schema and tables | Data is stored in an unstructured or semi-structured form such as JSON, XML. |
Altering Table Structure | Impacts applications | Minimal impact to the application interface |
Normalization | Expect to normalize the database tables as a general best practice for OLTP/operational applications and denormalization or dimensional model for OLAP applications | Data can be stored in a denormalized way |
Cost | Expensive servers | Low-cost commodity servers |
Scalability | Relational databases are vertically scalable (scale-up), i.e., when load increases on the database, then the server’s hardware capacity (Memory, CPU) should be increased. | NoSQL databases are horizontally scalable by adding more commodity servers to the cluster (scale-out) |
Designing a Document Store
In NoSQL database design, the initial step is to identify the entities and attributes and determine how the entities should be grouped. This is based on how the application accesses the datan. NoSQL design contains characteristics of data in groups, and these groups can have denormalized data for easier access and can change on “read” and “write” operations. In a relational database, the data is stored in a fixed set of columns. The data in these columns should be atomic and need to be normalized to maintain the consistency and integrity of the data. It’s difficult to change as the schema must be designed in advance.
Any database design starts with data analysis and how the data is related by identifying the objects and their relationships. Analyzing the data can be done in the following sequence of steps.
- Understand the requirements of the applications.
- Identify objects and data elements of those objects
- Define how to identify and access the objects
- Create a conceptual model representing the objects and relationships.
- Identify the data element(s) that makes the object unique to become the candidate key. It can be an existing business key or a system-generated id.
In NoSQL design, we don’t need to worry about normalization. It’s common to duplicate data in design. Just like in relational databases, access patterns (the way data is accessed and what data is accessed) are essential in NoSQL design. The best design would meet multiple access needs with the same structure. Data retrieved together should be stored together, resulting in better performance. We need to determine the search criteria to be used. Data retrieval is more efficient if the search is always on the key. We may need to create indexes on the columns used in the search criteria. This depends on the database that we use for the document store.
A document store is a collection of documents such as JSON (JavaScript Object Notation), XML, etc. JSON is a lightweight document, generally representing data elements, objects, and arrays.
How is a JSON document designed? Identify the relevant entities required for the business process. Identify the root entity with which the data would be accessed within a document. Identifying the root is the core concept. and the rest of the document structure is determined by the entities closest to the root entity. We need to understand the distinction between simple data elements and objects comprising data elements, then decide what data needs to be duplicated or denormalized.
Data element: It’s an attribute with a value.
“CustomerID”:”10001″
Object Group of data elements.
"Address":{
"Addresstype":"Shipping",
"Addressline1":"420, Gable Stone Ln",
"City":"Columbus",
"Country":"USA"
}Array: Collection of objects or values.
"Address":[{
"Addresstype":"Shipping",
"Addressline1":"420, Gable Stone Ln",
"City":"Columbus",
"Country":"USA"
}
,
{
"Addresstype":"Billing",
"Addressline1":"202, N.Cave Creek Dr",
"City":"Phoenix",
"Country":"USA"
}]
Here is an example of a customer record with the customer id, “10001,” stored in a relational database versus a NoSQL database as a JSON document. Customer data forms the root entity for the JSON and Customer address, and email addresses are sub-entities that are close to the root entity.
Relational Model

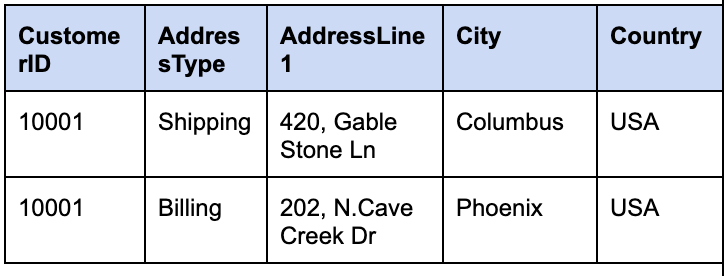
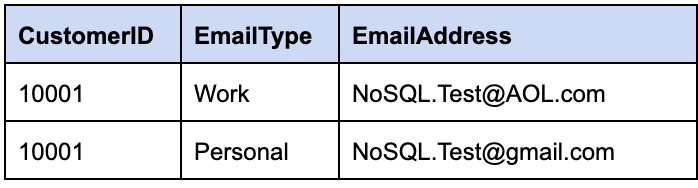
NoSQL JSON Document
{
"CustomerID":"10001",
"FirstName":"NoSQL",
"LastName":"Test",
"DateOfBirth":"08/29/1978",
"CustomerAddresses":
{
"Address":[{
"Addresstype":"Shipping",
"Addressline1":"420, Gable Stone Ln",
"City":"Columbus",
"Country":"USA"
}
,
{
"Addresstype":"Billing",
"Addressline1":"202, N.Cave Creek Dr",
"City":"Phoenix",
"Country":"USA"
}]
},
"EmailAddresses":{
"EmailAddress":[
{
"EmailType":"Work",
"EmailAddress":"[email protected]"
},
{
"EmailType":"Personal",
"EmailAddress":"[email protected]"
}
]
}
}
Document Store Design Patterns
Nested Vs. Related
A JSON can be created with all different objects and relationships in the same JSON document called a “Nested JSON.” In Related JSON, the relationships are stored in a separate JSON document with reference to the parent/child document. The following factors decide whether to create a Related document or a Nested document.
- If the Data reads/writes are only on the parent fields, then the documents should be created as separate Related documents.
- If the Data reads/writes are both on the parent and child attributes, then the JSON should be created as a Nested document.
- If the Relationship is One-to-one or One-to-many, then the JSON should be a Nested document.
- If the Relationship is a Many-to-one or Many-to-many, then the JSON should be a Related document.
- If there are more concurrent inserts/updates to the JSON document, then it is a best practice to create a Related document.
Nested JSON document
{
"CustomerID":"10001",
"FirstName":"NoSQL",
"LastName":"Test",
"DateOfBirth":"08/29/1978",
"CustomerAddresses":
{
"Address":[
{
"Addresstype":"Shipping",
"Addressline1":"420, Gable Stone Ln",
"City":"Columbus",
"Country":"USA"
} ,
"Address":{
"Addresstype":"Billing",
"Addressline1":"202, N.Cave Creek Dr",
"City":"Phoenix",
"Country":"USA"
}
]
}
}
JSON document with reference
{
"CustomerID":"10001",
"FirstName":"NoSQL",
"LastName":"Test",
"DateOfBirth":"08/29/1978"
"CustomerAddresses":{
“Address”:[{
"AddressID":"20001"
},
{
"AddressID":"20002"
}
]
}
}
"AddressID":"20001":
{
"AddressID":"20001",
"Addresstype":"Shipping",
"Addressline1":"420, Gable Stone Ln",
"City":"Columbus",
"Country":"USA"
}
"AddressID":"20002":
{
"AddressID":"20002",
"Addresstype":"Billing",
"Addressline1":"202, N.Cave Creek Dr",
"City":"Phoenix",
"Country":"USA"
}
Top-down and Bottom-up References
When modeling the data, we define the object id, attributes, and define how the objects relate to each other. There are two methods to store the data in JSON documents:
- Top-down model
- Bottom-up model
We need to determine the model to be used based on the data access pattern. If the pattern is to access parent objects, then the relationships should be top-down. If the child objects are accessed first, then the relationships should be defined bottom-up. In the Top-down model, foreign key references to child objects are stored within the parent object, and in the Bottom-up model, foreign key references to the parent object are stored in the child objects. The relationships in Top-down and Bottom-up models are depicted below.
Top-down References
"Customer":
{
"CustomerID":"10001",
"FirstName":"NoSQL",
"LastName":"Test",
"DateOfBirth":"08/29/1978"
"CustomerAddresses":[
“Address”: {
"AddressID":"20001"
},
{
"AddressID":"20002"
}
]
}
"AddressID":"20001":
{
"AddressID":"20001"
"Addresstype":"Shipping",
"Addressline1":"420, Gable Stone Ln",
"City":"Columbus",
"Country":"USA"
}
"AddressID":"20002":
{
"AddressID":"20002"
"Addresstype":"Billing",
"Addressline1":"202, N.Cave Creek Dr",
"City":"Phoenix",
"Country":"USA"
}
Bottom-up References
"Customer":
{
"CustomerID":"10001",
"FirstName":"NoSQL",
"LastName":"Test",
"DateOfBirth":"08/29/1978"
}
"Address":”20001”
{
"CustomerID":"10001",
"Addresstype":"Shipping",
"Addressline1":"420, Gable Stone Ln",
"City":"Columbus",
"Country":"USA"
}
“Address”:”20002”
{
"CustomerID":"10001",
"Addresstype":"Billing",
"Addressline1":"202, N.Cave Creek Dr",
"City":"Phoenix",
"Country":"USA"
}
One-to-One Relationship
Consider the following example of a One-to-One relationship where the CustomerID is referenced in the address document. If the address data is retrieved with the Name as search criteria, then there would be multiple hits to the database to retrieve the address. In this case, nesting the address document within the Customer document would be the optimal choice.
{
CustomerID: "JSON",
Name: "JSON Test"
}
{
CustomerID: "JSON",
AddressLine1: "202, N Cave Creek Dr",
City: "Phoenix",
State: "AZ",
Zip: "43054"
}
One-to-Many Relationship
When designing a One-to-Many relationship, creating a JSON document can either be a Nested or Reference document. There is a size limit for a document in Document Store databases. Therefore, Nested document is not always a choice. For example, in a system log relationship, one host can have thousands of logs, and in that case, a Nested document is not a good choice. Instead, creating a separate document with reference to the parent document would be an optimal choice.
{
CustomerID: "JSON",
Name: "JSON Test"
}
{
CustomerID: "JSON",
AddressLine1: "202, N Cave Creek Dr",
City: "Phoenix",
State: "AZ",
Zip: "53044"
}
{
CustomerID: "JSON",
AddressLine1: "101, Gable Stone Ln",
City: "New Albany",
State: "OH",
Zip: "43054"
}
A Nested document is preferred for low-cardinality child relationships (example: Customer and Address where a customer does not usually have many addresses). The choice of creating a Nested or a Related document also depends on how the data is read/written. If the child objects are frequently updated, then creating a Related document is a better option. There are pros and cons to creating a Related document as it requires reading twice to get the details of the child document. If it’s a Nested document, then all the details are available by reading the document once.
Two-way Referencing
When creating a Related document, a reference can be created either in the parent document or in the child document, as discussed earlier in the Top-Down and Bottom-Up references. There are advantages to creating a reference in both parent and child documents. That is, referencing the child in the parent document and referencing the parent in the child document. For example, in our customer address relationship, a reference to address created in the customer document and a reference to customer created in the address document would make it easy to access all the addresses belonging to one customer. The downside is multiple updates to all the children referring to the parent document if there is an update to the CustomerID. Following two-way referencing would not allow atomic updates (updating the entire document in one operation).
{
CustomerID: "JSON",
Name: "JSON Test",
AddressID: “10001”
}
{
CustomerID: "JSON",
AddressID: “10001”,
AddressLine1: "202, N Cave Creek Dr",
City: "Phoenix",
State: "AZ",
Zip: "53044"
}
Denormalizing
Denormalizing is allowed in some cases to eliminate the need to perform additional joins; however, it increases the complexity of the updates. Looking at the same Customer Address design, City is denormalized by adding an attribute to the customer document. It would be easier to retrieve all the customers in a city, but this would add complexity when the customer changes the city requiring multiple updates to Customer document and the Address document.
{
CustomerID: "JSON",
Name: "JSON Test",
City: “Phoenix”
}
{
CustomerID: "JSON",
AddressID: “10001”,
AddressLine1: "202, N Cave Creek Dr",
City: "Phoenix",
State: "AZ",
Zip: "53044"
}
Denormalizing makes sense when there are more reads than writes. If the requirement is to read the data frequently and update rarely, then it is okay to pay the price of complex updates to allow more efficient queries.
Summary
It is very important to know the access patterns before designing a NoSQL database to meet the functional and non-functional requirements. Designing and working with NoSQL databases is different from a Relational database, though some aspects are common to both. If you have questions or need help with NoSQL database design and development, please engage with us via comments on this blog post or reach out to us here.