
SQL Server Integration Services offers a useful tool to analyze data before you bring it into your Data Warehouse. The Profile Task will store the analysis in an XML file, which you can view using the Data Profile Viewer. Before we review how to use the Profile Task, let’s take a look at the eight types of profiles that can be generated by this control.
- Candidate Key Profile Request
- Use this profile to identify the columns that make up a key in your data
- Column Length Distribution Profile Request
- This profile reports the distinct lengths of string values in selected columns and the percentage of rows in the table that each length represents. Use this profile to identify invalid data, for example a United States state code column with more than two characters.
- Column Null Ratio Profile Request
- As the name implies, this profile will report the percentage of null values in selected columns. Use this profile to identify unexpectedly high ratios of null values.
- Column Pattern Profile Request
- Reports a set of regular expressions that cover the specified percentage of values in a string column. Use this profile to identify invalid strings in your data, such as Zip Code/Postal Code that do not fit a specific format.
- Column Statistics Profile Request
- Reports statistics such as minimum, maximum, average and standard deviation for numeric columns, and minimum and maximum for datetime columns. Use this profile to look for out of range values, like a column of historical dates with a maximum date in the future.
- Column Value Distribution Profile Request
- This profile reports all the distinct values in selected columns and the percentage of rows in the table that each value represents. It can also report values that represent more than a specified percentage in the table. This profile can help you identify problems in your data such as an incorrect number of distinct values in a column. For example, it can tell you if you have more than 50 distinct values in a column that contains United States state codes.
- Functional Dependency Profile Request
- The Functional Dependency Profile reports the extent to which the values in one column (the dependent column) depend on the values in another column or set of columns (the determinant column). This profile can also help you identify problems in your data, such as values that are not valid. For example, you profile the dependency between a column of United States Zip Codes and a column of states in the United States. The same Zip Code should always have the same state, but the profile discovers violations of this dependency.
- Value Inclusion Profile Request
- The Value Inclusion Profile computes the overlap in the values between two columns or sets of columns. This profile can also determine whether a column or set of columns is appropriate to serve as a foreign key between the selected tables. This profile can also help you identify problems in your data such as values that are not valid. For example, you profile the ProductID column of a Sales table and discover that the column contains values that are not found in the ProductID column of the Products table.
To use the Data Profile task follow these steps.
1) Start an Integration Services project and copy the Data Profiling Task to the Control Panel
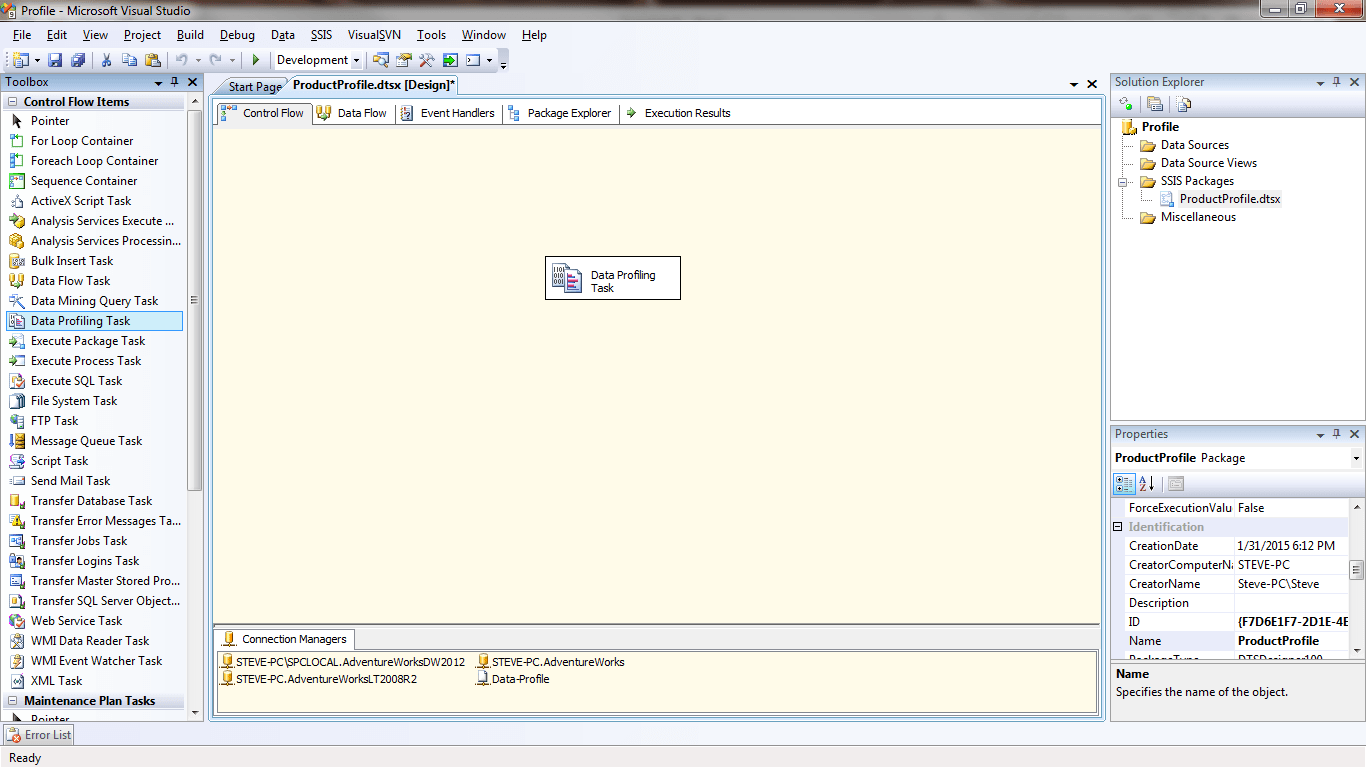
Adding a Data Profiling Task
2) Double click on the Data Profiling Task, the following dialog will appear where you can set the destination for the XML file that will hold the profile analysis.
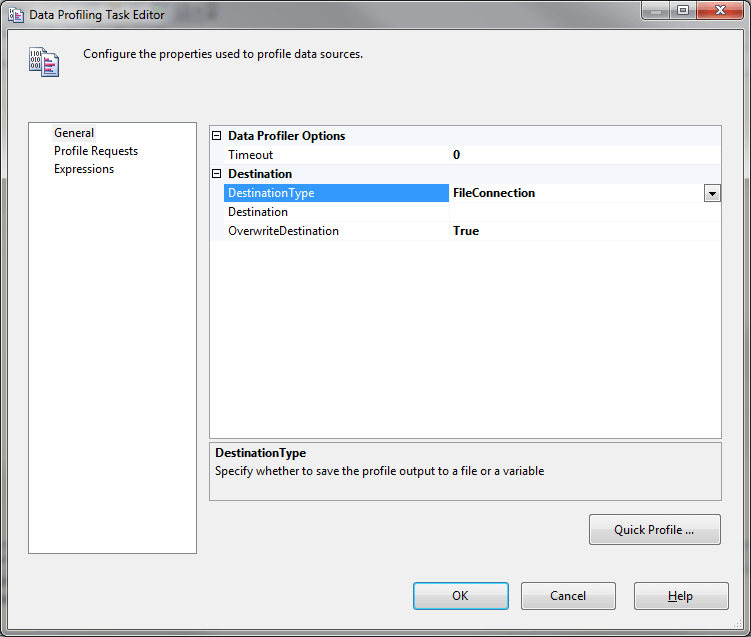
Data Profiling Task Editor
3) Select DestinationType and choose FileConnection, then select Destination and choose <New File connection…>, the following dialog will appear.

Profile Task Results File Location
4) Select Usage type, and choose Create File, browse to the location you want to hold the Data Profile XML file and give it a name. The dialog will look something like the following.
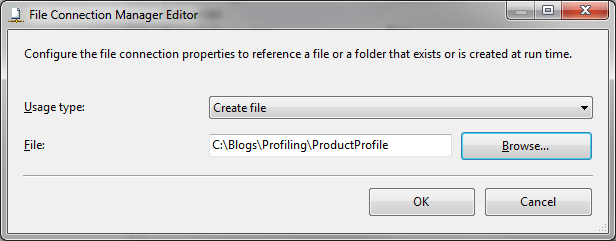
Choose the type and location of the Profile results
5) Click OK and then select Profile Requests in the Data Profiling Task Editor. You will see a list of all the Profile types you can generate. We will generate just the Functional Profile as shown below, select Functional Dependency Profile Request from the View drop down option.
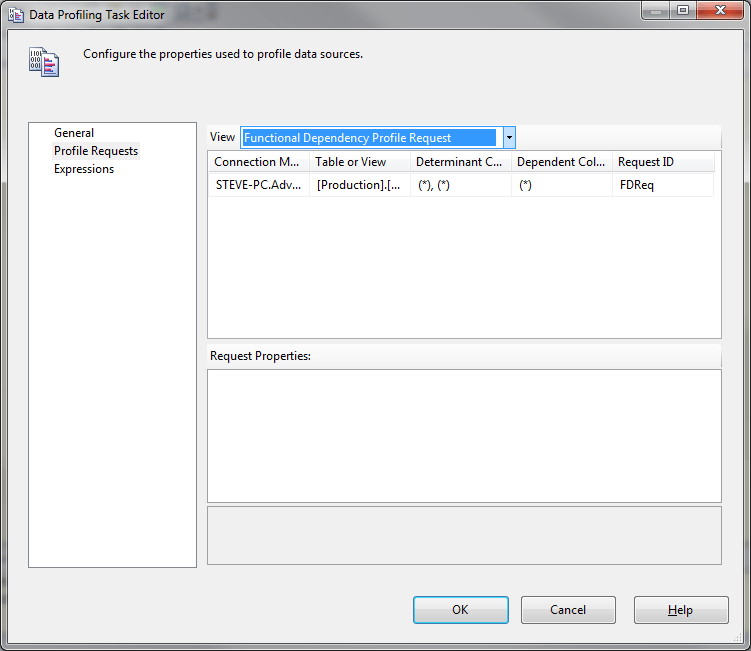
Profile Request Selection
6) We want to run this profile on the ProductSubcategoryID column against all other columns in the Product table. Click on the row in the pane below the View option to display the entries in the Request Properties pane.
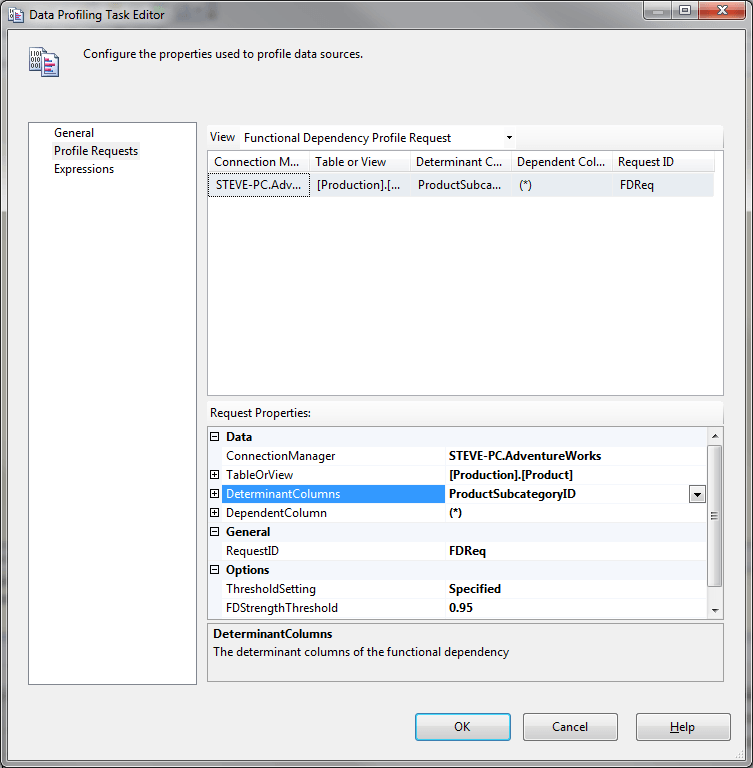
Profile Request – Functional Relationship
7) The Determinant column is the column that determines the values of the other columns. For example if we had a table of US State codes and State names, then the code column is the determinant column and the name column is the dependent column. We need to identify what those columns are for the Product table. In the Request Properties pane select the DeterminantColumns option and in the drop down dialog, remove the wild card selections and select the ProductSubCategoryID column.
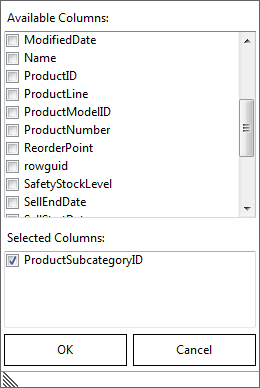
Functional Request Determinant Column
8) Leave the asterisk in the DependentColumn option, this wild card character indicates that ProductSubcategoryID should be compared against every column in the Product table. Please note the FDStrengthThreshold option. This option allow us to specify the threshold which determines when a Functional Relationship exists between any two columns. In this example we are saying that if less than 95% of the rows in the table don’t have the same values in two columns, then those columns do not have a Functional Relationship and won’t be reported in this profile.
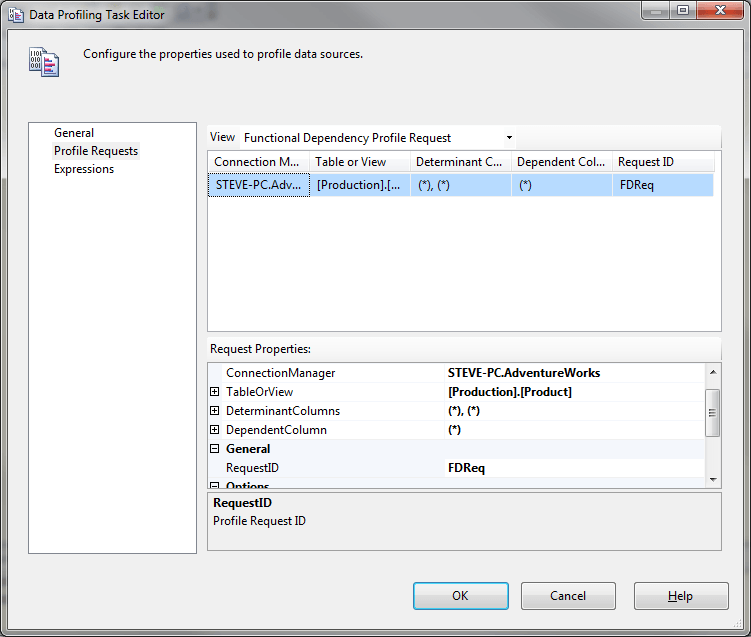
Profile Request Properties
9) Click the OK button and then run the package. When the package completes successfully, you will have an XML file in the location you specified in Step 4. You can use the Data Profile Viewer to view the XML file. The viewer application can be found in the Integration Services folder under the Microsoft SQL Server 2008 R2 folder.
Profile Viewer
10) The Data Profile Viewer will open a Dialog that will allow you to specify the path to the XML file you created. If you don’t see your XML file, make sure you specified the XML extension when you entered the name in Step 4, if you didn’t just add the extension to the file name.
Data Profile Location
11) Click on the Function Dependency Profiles option under the Product table. The Functional Dependency Profiles pane shows our chosen Determinant column, ProductSubcategoryID, and the other columns from the table in which at least 95% of the rows had the same pair of values in the Determinant and Dependent columns.
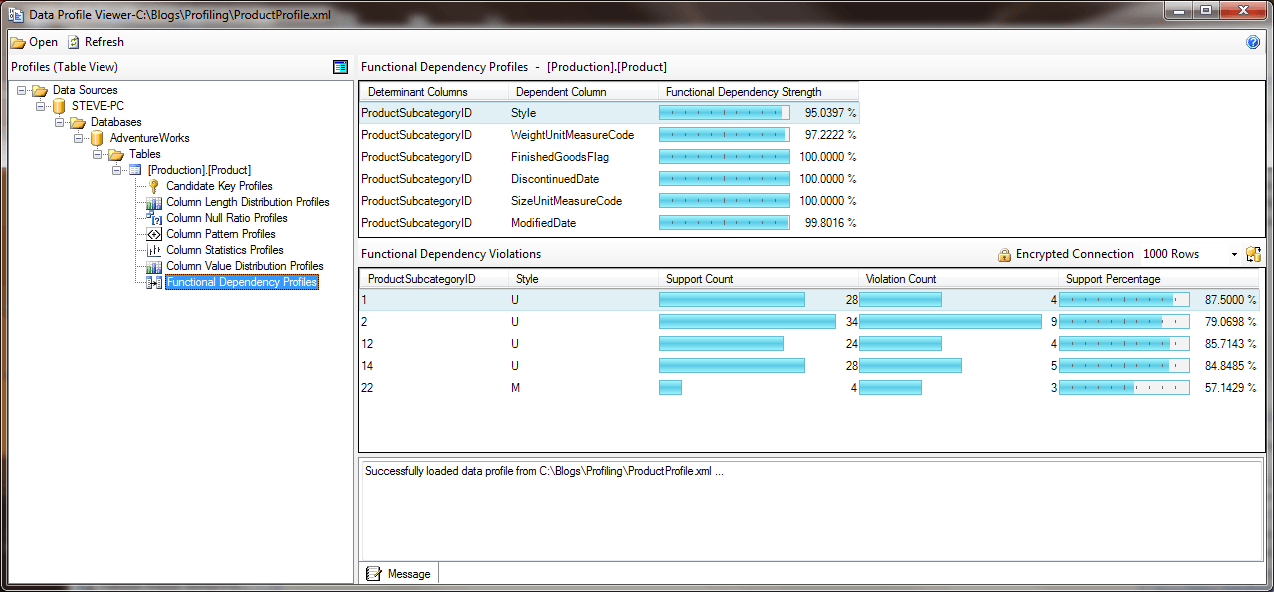
Functional Dependency Profile Results
12) With the Style Dependent column selected in the Functional Dependency Profiles pane we see in the Functional Dependency Violations pane there are five sets of ProductSubcategoryIDs that have values in the Dependent Style column that deviate from the majority of values for the ProductSubcategoryID. Double click on ProductSubcategoryID 14 in the Functional Dependency Violations pane. The Functional Dependency Profiles pane now shows the rows that support the functional dependency and those that are in violation for ProductSubcategoryID 14.
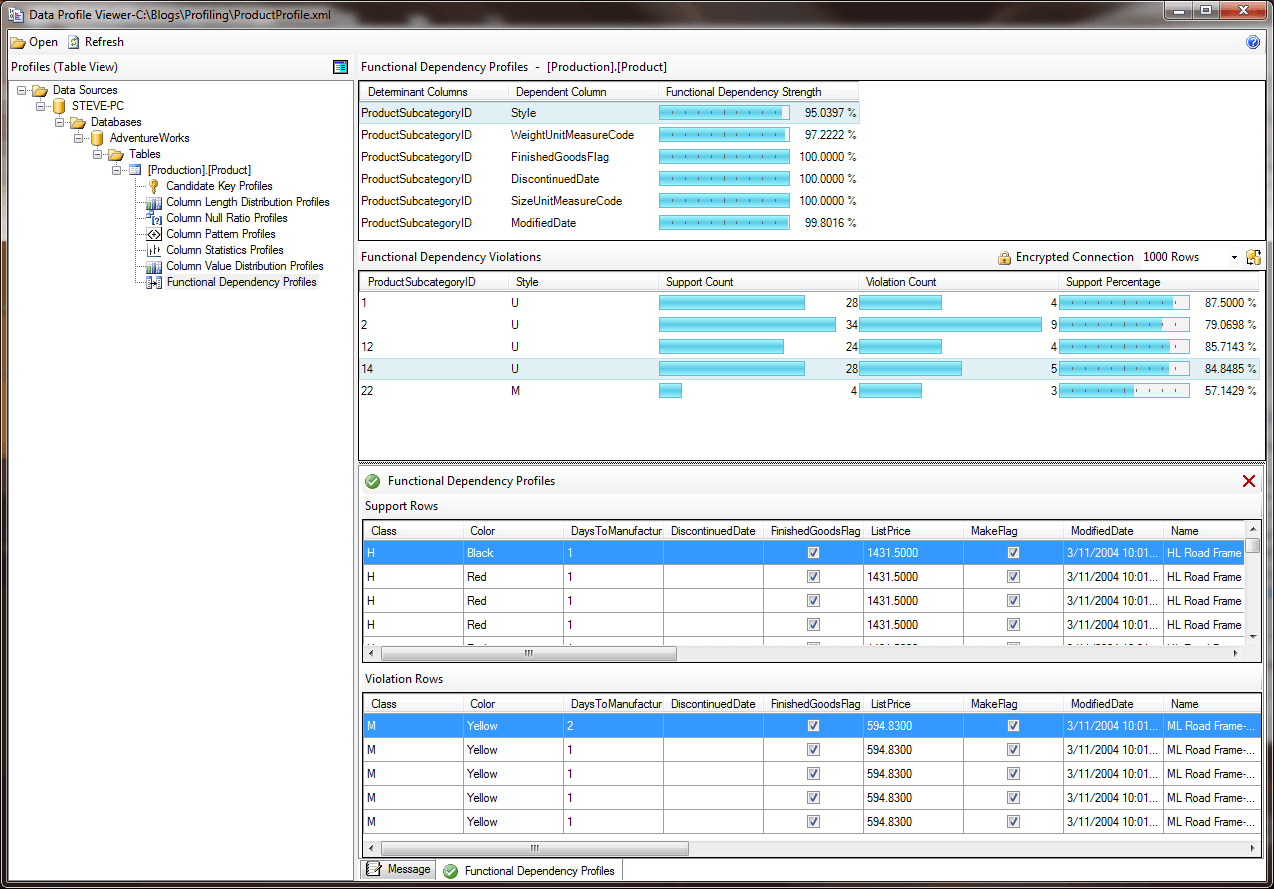
Functional Dependency Results with Support and Violation Rows
13) In the Functional Dependency Violations grid, we can see that for a ProductSubcategoryID of 14 there is a Support Percentage of 84.8485 percent for the Style column. This means that there were 33 rows with a ProductSubcategoryID of 14, and of those rows 28 of them had a U in the Style column while the remaining 5 had some other value. To see the detail behind this, click on the row in the Functional Dependency Violations grid, and the Supported Rows and Violation Rows will be shown in two grids below. Now you can see exactly what the values of the Style column were for the Violation rows, in this case they were all W.
Determining whether or not this identifies a problem in the data is up to someone with business knowledge of the Product table. The purpose of the Data Profile Task is to alert us to potential issues and guide us on where to look in the data.
This and the other seven profile requests offered in the Data Profiling Task, can ease your burden when it comes time to profile new unknown data sets.