
SUMMARY:
The Informatica MDM Match-Merge process is a fundamental Master Data Management (MDM) function that utilizes configurable match columns and rules (including Fuzzy and Exact strategies) to identify duplicate records from various source systems and automatically or manually consolidate them to create a single, authoritative “golden copy” of the record.
- The match process identifies similar or identical records in the base object using match columns and match rules, determining whether consolidation candidates require Data Steward review or automatic merging.
- The system employs two primary strategies: Exact Match, which is faster and compares records with identical column values, and Fuzzy Match, which is slower but makes probabilistic determinations based on data variations like misspellings or phonetic changes.
- Following the matching strategy, the consolidation process updates the record’s Consolidation Indicator status in the base object, moving it from a New Record (4) to a Matched Record (3), then queuing it for merge (2), until it is flagged as the “golden” Best Version of Truth (BVT) (1).
- Match rules are highly customized using Match Rule Sets that define Search Levels (e.g., Narrow, Typical, Exhaustive) and Match Levels (e.g., Typical, Conservative, Loose) to control the scope and accuracy of generated match candidates.
Effective configuration of the base object, including selecting appropriate fuzzy key properties like Key Type (Person Name, Organization Name) and Key Width, is essential to achieving optimal match pairs.
Table of contents
Overview
Implementing a Match-Merge process is very common as part of Master Data Management. In a nutshell, this process involves taking data from different source systems and finds the possible duplicates, or identical match (and merge as required) to create a golden copy of the record. The Match-Merge process can be both real-time (instant) or batch followed by an approval process to confirm the golden copy of the record.
Match Process
The match process uses match columns and match rules to:
- Identify similar or identical records in the base object.
- Determine candidate records for automatic consolidation.
- Determine candidate records for review by a Data Steward prior to consolidation.
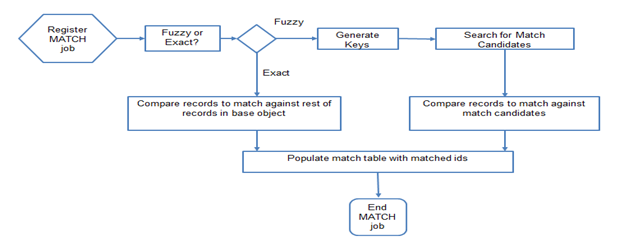
The match process uses base object columns (Match columns) to identify the matches. In Informatica MDM, the match process has two main strategies (Fuzzy Match and Exact Match) to compare records and identify duplicates. We use one of these matching strategies or both of them when the base object is configured as a fuzzy base object. We need to understand the data to identify the candidate data objects to go through the Match-Merge process.
Fuzzy Match: Fuzzy matching is the most used and slow in process because it identifies the match records in base objects. Fuzzy matching makes probabilistic determination of match between records based on variations in data patterns such as misspellings, transpositions, the combining or splitting of words, omissions, truncation, and phonetic variations.
Exact Match: Exact matching is faster because it compares records with identical values in the match columns.
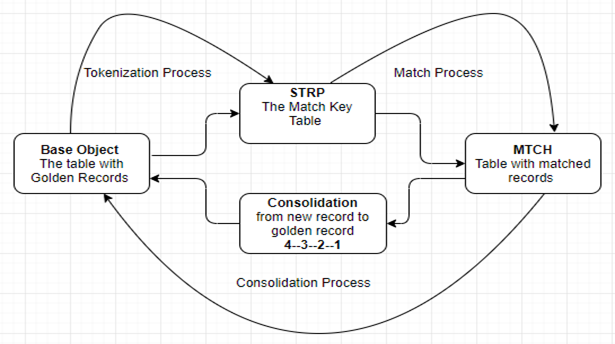
Match process is triggered after the tokenization process as it uses the match key tokens to match the records. Match tokens are generated by SSA_NAME3 Algorithm.
Consolidation and Merge Process
Based on the Matching strategy, the consolidation will begin. Here the Match table (_MTCH) is populated with the matched records that are identical or duplicate with the ROWID_OBJECT and the Consolidation Indicator in the base object of these records changes from 4 (New Record) to 3 (Matched Record). These records are then queued with the Consolidation Indicator as 2 indicating that they are ready to go for the merge process. The merged data (records) are flagged with the Consolidation Indicator 1 indicating that the records can be considered as “golden” (Unique or BVT – Best Version of Truth).
Match and Merge Rules Configuration
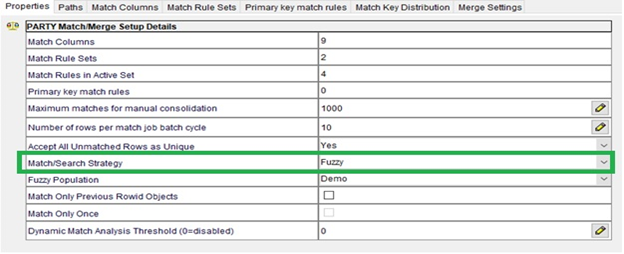
In order to perform the match process, we need to configure the base object to Fuzzy base object or Exact base object, choose the match columns (to be used for comparison) and define the match rule sets. We configure match rules that can identify and queue up duplicate records or identical records for the merge.
We have the flexibility to configure the exact match strategy with fuzzy logic if the base object is configured to Fuzzy. We cannot define the fuzzy logic if the base object is configured to Exact.
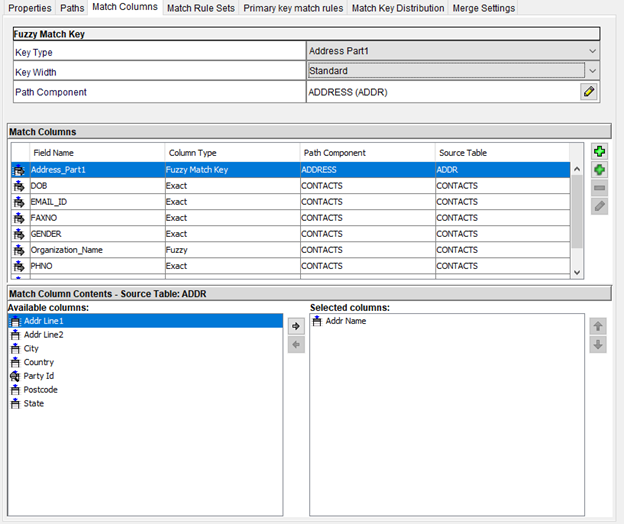
Match Columns
Select the appropriate columns to be used in the match process and configure the fuzzy match keys. Here we can add both fuzzy key columns and exact key columns as the base object is configured to fuzzy base object. These types of match columns and match rule configuration provide the best match pairs.
Fuzzy match key has the following properties:
- Key Type: It has three options — Person Name, Organization Name, Address Part 1 (the SSA_Name3 algorithm generates the token patterns based on Key Type).
- Key Width: Defines to what extent the search needs to be performed. It has four options — “Standard,” “Extended,” “Limited,” and “Preferred” (the recommended option is “Standard”).
- Path Component: Provides a way to define the relationship between parent and child tables using foreign keys. The columns from child table are used as match columns.
Match Rule Sets
A Match Rule Set is a collection of match columns and a definition of match rules (comparison criteria for duplicates check). These are configured based on different requirements to fulfill different needs at different times. Create a Match Rule and define the Search Level. The match candidates are searched based on Search Level.
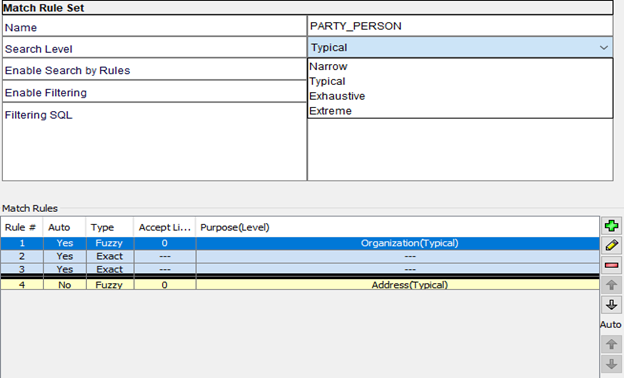
Search Levels: We have four options to choose from
- Narrow: Limits the search
- Typical: Gives appropriate match candidates
- Exhaustive: Generates more match candidates that might not be considered
- Extreme: Generates more match candidates compared to Exhaustive search level
Enable Search by Rules: This property is used only for fuzzy logic search and the “Enable Filtering” property is used for SQL-based filtering of match candidates.
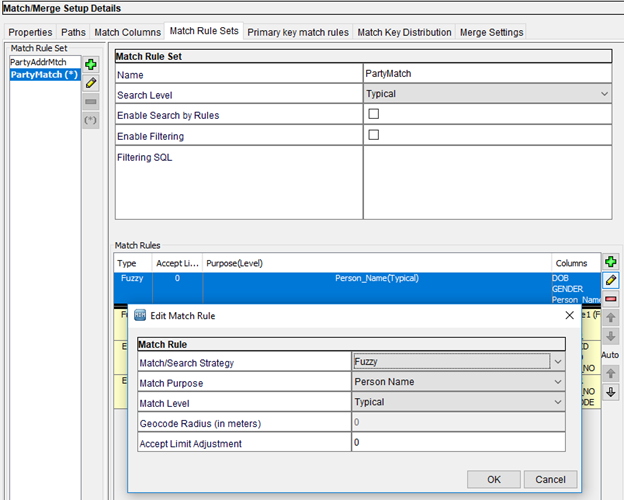
Match/Search Strategy: Based on this, we can configure match purpose and related properties. This is only for fuzzy base object and fuzzy columns.
Match Purpose: Match Rules are applied and match candidates are generated based on the Match Purpose. We can find the Match Keys that are generated via the tokenization process. We have different options under Match Purpose (Person Name, Individual, Resident, Contact, Address, Division, Organization, Household, etc.).
Match Level: Indicates the accuracy level of the fuzzy match. It has the following options:
- Typical: Suitable and applicable for most of the matches
- Conservative: Produces fewer matches relative to Typical level (this is called “Undermatching”).
- Loose: Produces more matches relative to Typical level (this is called as “Overmatching”).
Accept Limit Adjustment: It indicates the degree (level) of the match to be considered as an acceptable match for a given Match Rule. It is further refinement of the Match Level. The more positive the number is (example: 65 to 70+) gives the conservative/tight match and the more negative the number is (example: 50 to 45-) gives the loose match.
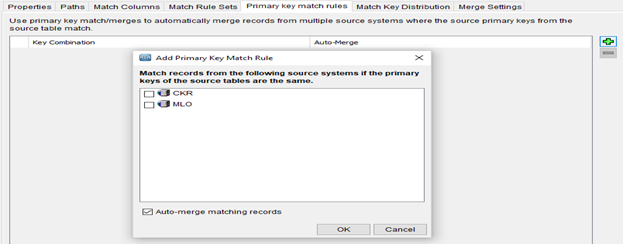
Primary Key Match Rules
This is used to match data from two source systems using primary key value. These matches are quick and accurate as the comparison is based on primary key. We need to select the source systems with the possibility of having identical primary key values to perform primary key matching.
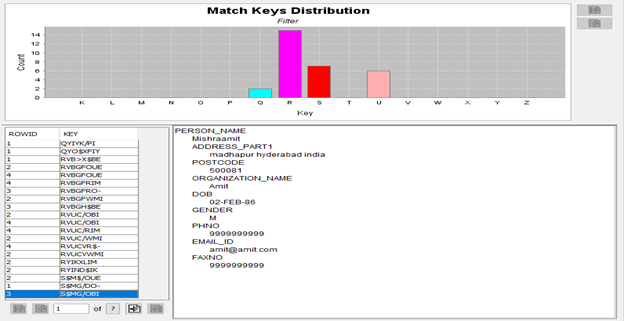
Match Key Distribution
Here we can find the Match Keys that are generated by the tokenization process. The match candidates are generated based on this.
Support Tables used in the Match Process
Match Key Table: C_baseObjectName_STRP. Example C_Employee_STRP
Match Table: C_baseObjectName_MTCH. Example C_Employee_MTCH
Summary
If you have questions on how to use Informatica MDM or need help with your Informatica MDM implementation/support, please engage with us via comments on this blog post, or reach out to us.