
The term Market Basket Analysis is self-explanatory. In short, it helps find the probability of the items frequently bought together by mining the large volume of transactions for items that were often purchased together. This helps understand the customer better, place the frequently bought items together, provide product recommendations, etc.
Multiple algorithms are available to perform Market Basket Analysis, but Apriori is the most frequently used algorithm because it is easy to use and technically simple.
Apriori Algorithm
Apriori is an unsupervised learning algorithm that uses the below three metrics. Confidence is the metric used to decide the probability of buying a pair/combination.
Support: Refers to the percentage of transactions that includes a particular product. We can remove products that are very rarely bought to speed up the computation.
Support = Number of transactions having item A / Total number of transactions
Illustration:
SELECT ITEM, * FROM DEMO_DB.DEMO_SCHEMA.TRANSACTIONS; -- 7501
SELECT ITEM, * FROM DEMO_DB.DEMO_SCHEMA.TRANSACTIONS
WHERE ITEM LIKE ALL ('%light cream%'); -- 117
Support(A) = SELECT 117/7501 = 0.015598
SELECT ITEM, * FROM DEMO_DB.DEMO_SCHEMA.TRANSACTIONS
WHERE ITEM LIKE ALL ('%chicken%'); -- 450
Support(B) = SELECT 450/7501 = 0.059992
SELECT ITEM, * FROM DEMO_DB.DEMO_SCHEMA.TRANSACTIONS
WHERE ITEM LIKE ALL ('%light cream%', '%chicken%'); -- 34
Support(A->B) = SELECT 34/7501 = 0.004533Confidence: Refers to how a product helped to buy another product.
Confidence = Number of transactions having items A and B /
Number of transactions having item A
Illustration:
Confidence = SELECT 34/117 = 0.290598Lift: Helps find the association’s strength.
Lift = (Support for A & B) / (Support A * Support B)
Illustration:
Lift = SELECT 0.004533/(0.015598*0.059992) = 4.844215583833Now let us get into the tools we are using for implementation.
Apriori Function:

Here is a description of the parameters used in the Apriori function:
transactions: Input data for this algorithm. It should be a Python Dataframe.
min_support: Specifies the minimum frequency of occurrence. There is no point in including an item that is rarely bought.
min_confidence: Represents the minimum influence of product cause to buy another product (it is like conditional probability: the probability of A given B, i.e., A|B).
min_lift: Represents the minimum likelihood of buying items together. If the lift’s value is zero, there is no motive between the given items. The pairs with high lift value mean those are the items frequently bought together.
min_length: It represents the minimum number of items to participate in the analysis. i.e., P(A, B, C), if min_length =3.
For min_length =2, the conditional probability is P(A,B) = p(A|B) p(B).
Suppose we extend this for three variables, as per the chain rule. In that case, the conditional probability is –
P(A,B,C) = P(A|B,C) P(B,C) = P(A|B,C) P(B|C) P(C)
max_length: It represents the maximum number of items to analyze for the association.
We can find the probability of any pair by changing the values for min_support and min_confidence.
Tools Used For Implementation
- Snowpark
- Virtual environment
- Snowflake
- Python
- Jupyter notebook
Start With Snowpark
Using Snowpark, we can easily access and process the data using programming languages like Python, Java, and Scala. From snowflake documentation, “The Snowpark library provides an intuitive for querying and processing data in a data pipeline. Using this library, you can build applications that process data in Snowflake without moving data to the system where your application code runs.“
Following are the steps to have Snowpark ready on the system.
Step 1: Install Conda to have the notebook on the machine.
Step 2: Snowpark currently supports Python 3.8 and above. You may have other applications running on different Python versions. So, we need to isolate the libraries needed for different applications. Create a virtual environment and enable it. I have created a virtual environment in this example and named it py38_env.
To do this, open an Anaconda prompt from the Anaconda navigator and submit the below command:
(base) PS C:\Users\farid> $ conda create --name py38_env -c https://repo.anaconda.com/pkgs/snowflake python=3.8 numpy pandasStep 3: Activate the new virtual environment by submitting the below command:
(base) PS C:\Users\farid> $ conda activate py38_env4Step 4: Install the Snowpark package.
(py38_env) PS C:\Users\farid $ conda install snowflake-Snowpark-pythonStep 5: Open a Jupyter notebook
(py38_env) PS C:\Users\farid> jupyter notebookCreating A Snowpark Session
First, run the pip install to add Snowpark API. Then, follow the code below to establish a Snowpark session and use.
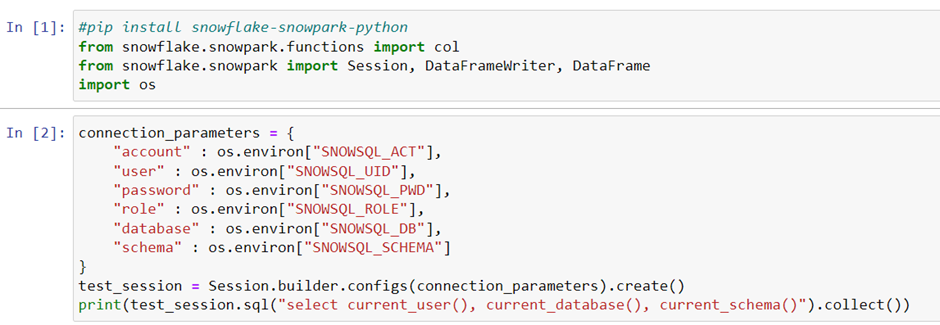
[Row(CURRENT_USER()='FARID', CURRENT_DATABASE()='DEMO_DB', CURRENT_SCHEMA()='DEMO_SCHEMA')]Fetching The Data From Snowflake

Here, Transactions is a table in Snowflake demo_db.demo_schema schema.
Inserting The Data Into The Snowflake

Here, we are pushing the data from the Python Dataframe df to Snowflake table demo_db.demo_schema.mba_Snowpark.
About Source Data Set
The source data file has a comma-separated list of products belonging to transactions. This data file I have loaded this into the Snowflake table DEMO_DB.DEMO_SCHEMA.TRANSACTIONS. Below is the snippet of the data file.
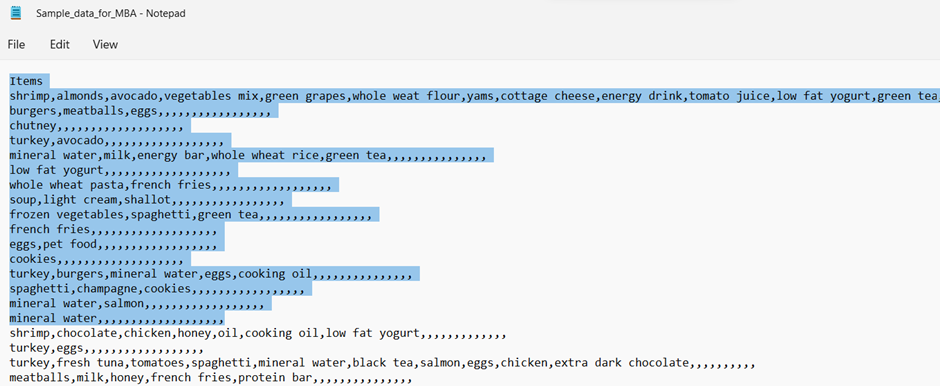
Use the below code snippet to load the sample file into Snowflake:
CREATE TABLE DEMO_DB.DEMO_SCHEMA.TRANSACTIONS(ITEMS VARCHAR);
CREATE STAGE DEMO_DB.DEMO_SCHEMA.MY_INTERNAL_STAGE;
CREATE FILE FORMAT DEMO_DB.DEMO_SCHEMA.MY_FILE_FORMAT
TYPE = CSV FIELD_DELIMITER = ',' SKIP_HEADER = 1;Here is a snapshot of the table:

The result of the Apriori function produces a tuple output. This tuple needs to be converted to a Python list and then load the result into Snowflake using Snowpark API.
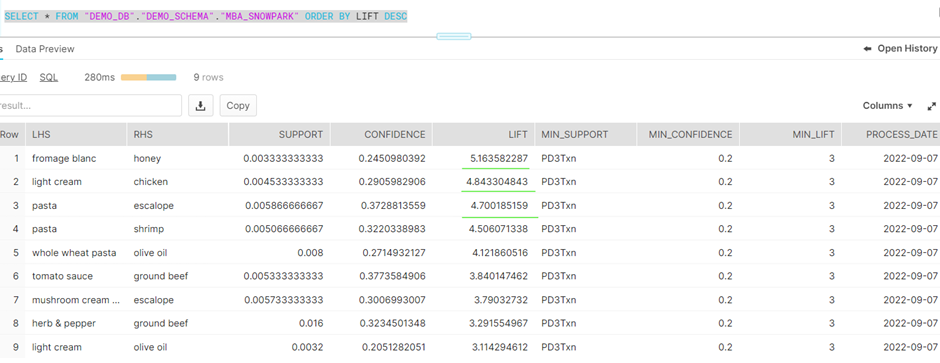
Let us place all these steps in a sequence to automate or run on an ad hoc basis using a single Python command.
Code:
#pip install snowflake-Snowpark-python
from snowflake.Snowpark.functions import col
from snowflake.Snowpark import Session, DataFrameWriter, DataFrame
import os
connection_parameters = {
"account" : os.environ["SNOWSQL_ACT"],
"user" : os.environ["SNOWSQL_UID"],
"password" : os.environ["SNOWSQL_PWD"],
"role" : os.environ["SNOWSQL_ROLE"],
"database" : os.environ["SNOWSQL_DB"],
"schema" : os.environ["SNOWSQL_SCHEMA"]
}
test_session = Session.builder.configs(connection_parameters).create()
print(test_session.sql("select current_account(), current_user(), current_database(), current_schema()").collect())
b = test_session.table("TRANSACTIONS").collect()
transactions = []
for i in range(0, 7500):
z=list(b[i].ITEM.split(","))
transactions.append(z)
#transactions
for i in range(0, 6):
print(transactions[i])
from apyori import apriori
rules = apriori(transactions = transactions, min_support = 0.003, min_confidence = 0.2, min_lift = 3, min_length = 2, max_length = 2)
results = list(rules)
from datetime import date
import pandas as pd
def inspect(results):
lhs = [tuple(result[2][0][0])[0] for result in results]
rhs = [tuple(result[2][0][1])[0] for result in results]
supports = [result[1] for result in results]
confidences = [result[2][0][2] for result in results]
lifts = [result[2][0][3] for result in results]
min_support = ['PD3Txn' for result in results]
min_confidence = [0.2 for result in results]
min_lift = [3 for result in results]
process_date = [date.today() for result in results]
return list(zip(lhs, rhs, supports, confidences, lifts, min_support, min_confidence, min_lift, process_date))
df = pd.DataFrame(inspect(results), columns = ['LHS', 'RHS', 'SUPPORT', 'CONFIDENCE', 'LIFT', 'MIN_SUPPORT', 'MIN_CONFIDENCE', 'MIN_LIFT','PROCESS_DATE'])
df
df.sort_values(by=['LIFT'], ascending=False)
ddf = test_session.create_dataframe(df)
ddf.write.mode("append").save_as_table("DEMO_DB.DEMO_SCHEMA.MBA_SNOWPARK")
test_session.table("DEMO_DB.DEMO_SCHEMA.MBA_SNOWPARK").show()Please contact us if you have any questions regarding this blog or need help with Market Basket Analysis or other machine learning services.