
Amazon Sagemaker Autopilot is used to build, train and deploy machine learning models. Sagemaker is useful for creating machine learning models without an in-depth knowledge of machine learning. It automatically evaluates the data, creates features and creates machine learning models. The Autopilot takes data as input, applies various machine learning algorithms and returns the optimal model.
However, Autopilot does not yet support complex machine learning like image classification and video inference. It is suitable for simple supervised learning tasks like regression and classification.
The advantages of using Autopilot are –
- Reduces development effort and provides the best algorithm
- Handles missing values
- Tunes hyperparameters
- Generates machine learning code as output
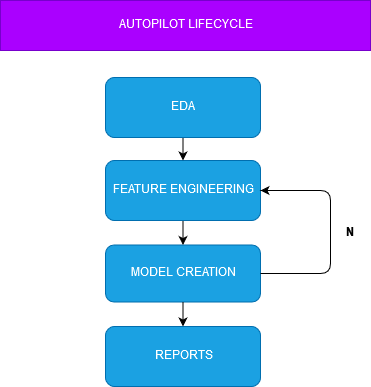
Hands-on Project
Below is an example of using Autopilot for binary classification. The model predicts whether the credit card request should be granted or denied.
Exploratory Data Analysis
The data is available at ics.uci.edu. The code is available at github. The data has 16 attributes and some missing values.
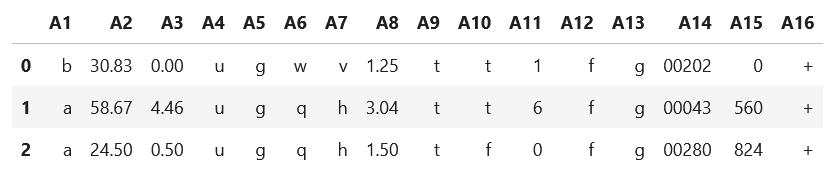
A16 is the target variable. It denotes whether a loan should be approved or denied.

Autopilot Implementation
It is a recommended practice to divide the data into train and test datasets. Store the datasets at S3 bucket.

Configure Autopilot with arguments. Specify the S3 bucket locations of input data and output folder. Autopilot creates notebooks and stores them at the output location.

The MaxCandidates argument denotes the number of models to be created. We need to specify the target variable, and optionally specify the problem type (the type of machine learning problem). Valid arguments for problem type are regression, binary classification, and multi-classification. If the target variable argument is not present, Autopilot would determine the type of machine learning problem.
Create an Autopilot job and start it. The job creates models and terminates after completion. Given below is the code for creating an Autopilot job.
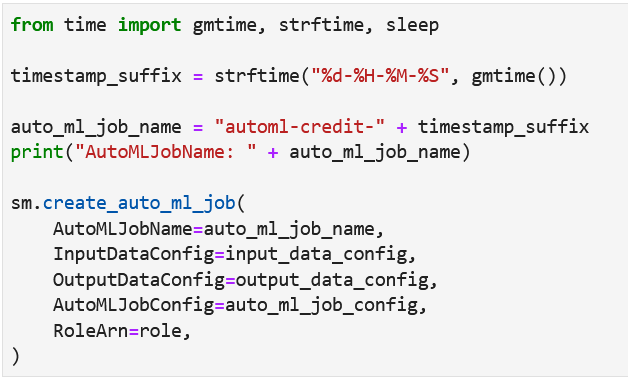
The Autopilot job creates child jobs for data analysis, feature engineering and model creation. These jobs can be viewed at Sagemaker > Training > Training jobs url.

After completion of the Autopilot jobs, we can view the best score from all the created models.
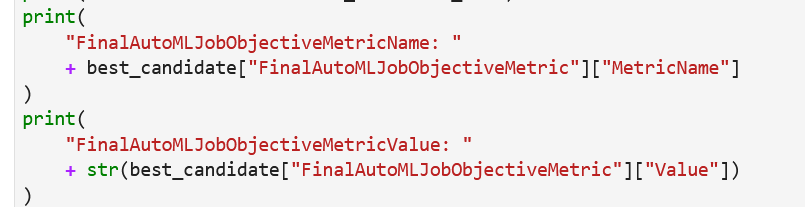

The notebooks from the Autopilot jobs are available at the S3 output path mentioned during the configuration step.

The candidate definition notebook has information on the optimal algorithm along with the hyper parameters values.
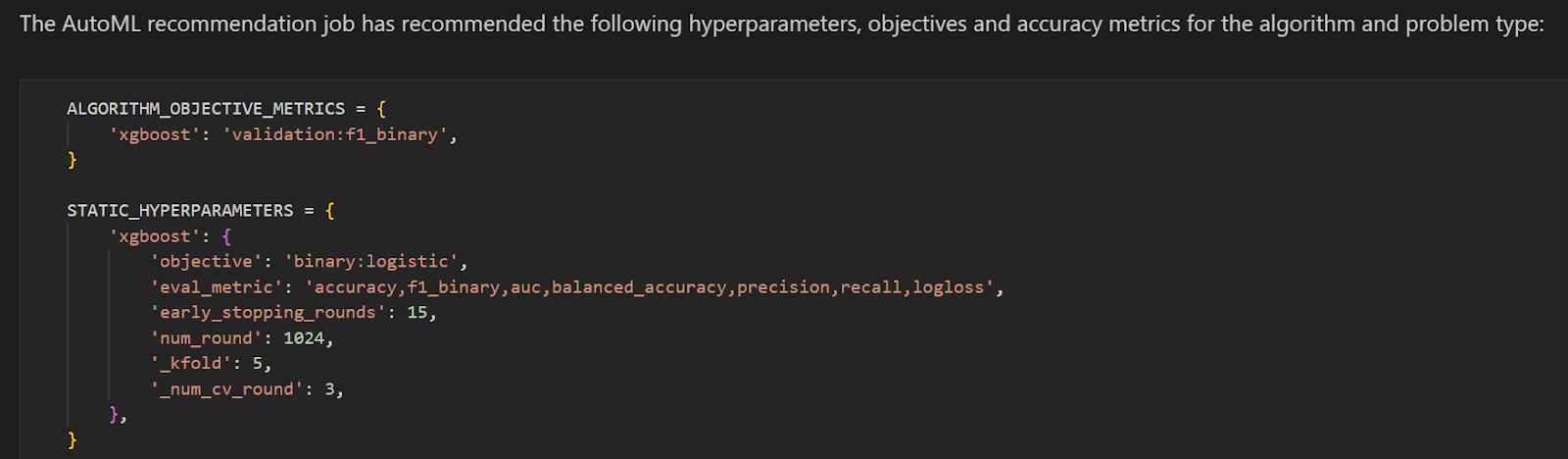
For the current credit card approval project, Autopilot recommends the XGBoost algorithm.
Reports
Autopilot creates reports that aid in understanding the optimal model. It creates two reports:
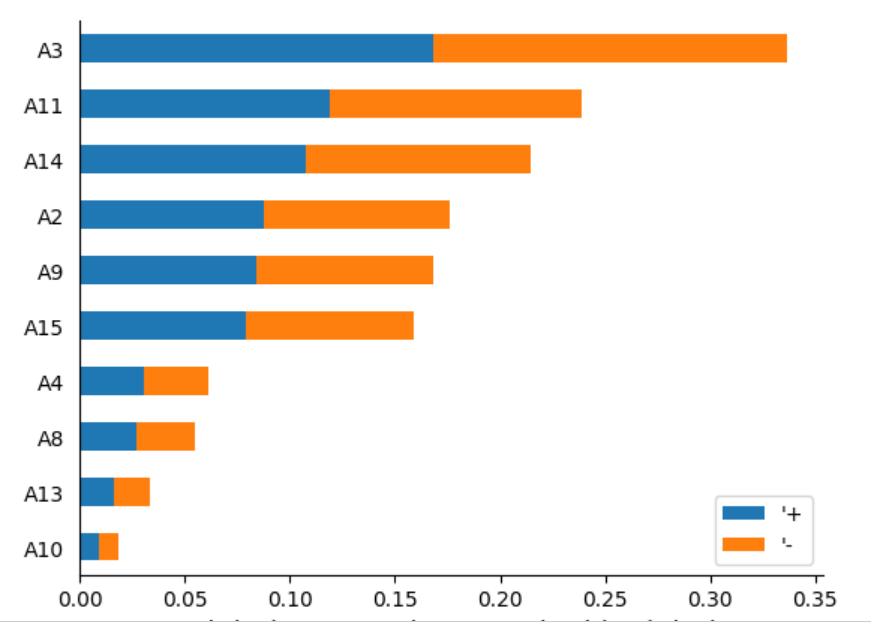
1. The Explainability Report which contains feature importance charts. It displays the importance of each attribute regarding the target variable. The Autopilot internally uses the KernelShap method for calculating the importance of features.
2. The Model Quality Report which contains the metrics and graphs of the selected model.
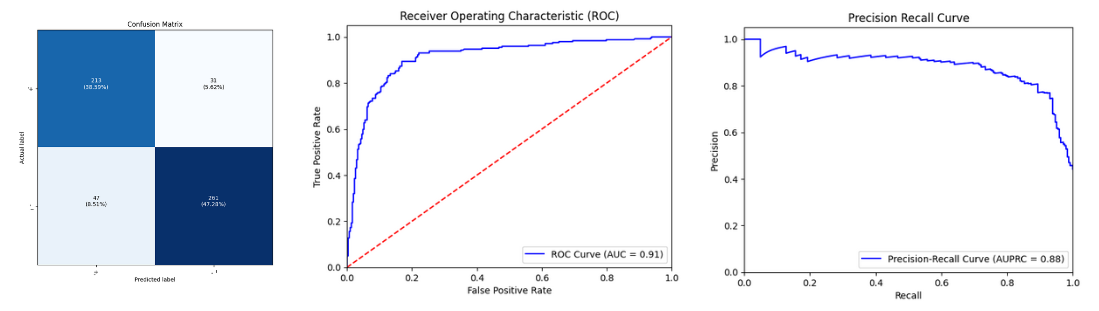
Shown below is the metrics table of the XGBoost model selected by Autopilot.

As the current project is a binary classification, the model quality report displays the confusion matrix ROC, and precision recall graphs of the optimal model.
If you have questions regarding AWS Sagemaker or need help with implementation/support, please contact us. We provide expert AI (artificial intelligence) and machine learning consulting.