
There has been a lot of buzz around cloud native and serverless development architectures over the past few years; the benefits of minimizing your administrative overhead and speeding time-to-market are undeniable, and these technologies are increasingly starting to make their way into the enterprise. With serverless application development, in particular, there are a number of differences in the way that an application is designed and implemented that must be taken into account when adopting this new software delivery paradigm. In this article, we cover some of the “gotchas” of serverless architecture implementation, focusing specifically on issues that may affect enterprise software development.
Make use of services whenever possible
One of the key tenets underpinning the serverless architecture style is that existing services should be preferred whenever possible; this allows development to focus on logic that is directly related to business use cases. Often in enterprise development, a significant amount of work is devoted to building and maintaining the backend systems that provide the plumbing required for your application to function; in the serverless world, the responsibility for these systems should be offloaded to the platform vendor whenever possible.
For example; when processing a lot of stream data in AWS, there are a number of services that can be leveraged to handle all of the plumbing required to ingest and process data streams; it is possible to write your own functions that receive, queue, and process the data contained in a complex data stream, but it is far more efficient to rely on AWS-provided services like Kinesis, S3, SQS, and Redshift to handle data ingestion, storage, and processing. Using these services allows you to offload responsibility for support and maintenance of the backend onto the cloud provider while relying on published service SLAs to determine your expected service availability.
Keep functions small and compartmentalized

One of the limitations of most serverless platforms is that they impose a hard limit on execution time for any individual function. In addition, the size of your function will impact the initial startup time for that function, exacerbating what’s commonly described as the cold start problem. The larger your function, the more significant the impact of the autoscaling backend will be on periodic cold starts, and the longer your function, the longer it will spend in execution (in general). A hallmark “best practice” for serverless application development is to keep your functions atomic; that is, write a function to perform one very specific thing, and where needed, break out more complex logic into multiple separate functions. This results in optimizations on the part of project management and development process; atomic functions are far easier to track as a single unit of work than larger, multipurpose application instances.
Plan your deployments carefully
Some of the advantages of serverless application development can also be the cause of its biggest pitfalls; most vendors make it extremely simple to author and deploy a serverless application with very little process. Indeed, on most platforms, a developer can literally log in and write function code directly in the console, with no deployment pipeline required. Obviously, this is not a best practice; at XTIVIA, we strongly recommend setting up a fully automated build pipeline for your serverless applications that mirror the type of process that you would use for traditional applications. This means leveraging standard delivery pipeline tooling such as Terraform, Jenkins, TravisCI, and Github in concert to deliberately plan and execute deployments to your serverless environments.
We were recently called on to rework a project where the development team had run into this gotcha; at the outset of the project, the developers had all been granted access to the AWS console to allow them to create and modify resources while the business refined the implementation plan. The well-intentioned intent was to get development moving quickly, without the “overhead” of an automated deployment pipeline; the folly of this approach was quickly made evident, as a lack of governance and standardization quickly led to difficulties integrating work done by different developers, and a lack of oversight on what resources were actually being provisioned in the AWS account. To remedy this, we had to reverse-engineer the target AWS environment and bring all resources under a standard composition and provisioning process automated using Terraform. The effort required to do so was significantly higher than it would have been if a standard automation process had been established at the project’s outset.
Secure your application

This item is particularly important for externally-facing applications, such as single-page applications, public APIs, and SaaS applications; it is absolutely critical to make certain that you have secured all public endpoints and services, and that access control throughout your application adheres to the principle of least privilege. Generally speaking, this requires use of both the serverless provider’s access control mechanic along with facilities that are usually built into services that provide public-facing endpoints, such as Azure API Manager, AWS API Gateway, and AWS Appsync. For the example of an AWS-hosted serverless single-page React application interfacing with Lambdas through an API Gateway instance, this means limiting the privileges of the Lambda functions and securing the S3 bucket and Cloudfront caches through the use of IAM Roles and Policies and setting up throttling and authorization on the API Gateway to avoid denial of service and API hacking attempts.
Most cloud providers do provide some built-in mechanisms to provide basic security out-of-the-box; for example, Amazon sets up default throttling on any API served through the API gateway to limit the potential impact of a denial-of-service attack:
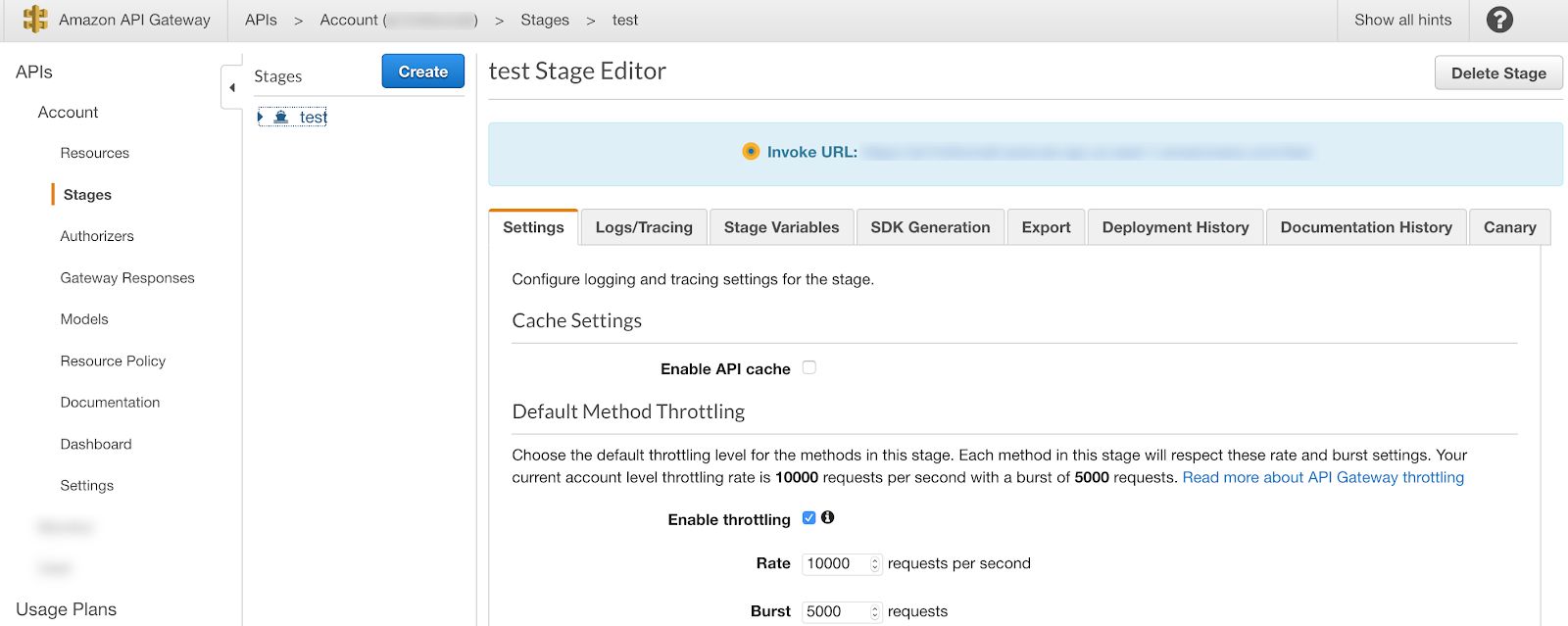
While the default rate of 10,000 requests per second does at least provide a basic safety net, it is strongly recommended that you tailor your throttling rate to fit the needs of your application. One quick note: while Amazon limits all newly-created APIs to 10,000 requests per second, that number can be increased upon request.
Serverless is not always the right choice.
Finally, it is critical to make sure that the development effort is one that is well-suited to a serverless-style architecture. A successful serverless application implementation will rely on stitching a number of independent services together, so this architectural pattern heavily favors use cases where asynchronous or detached processing capabilities are a good fit. Common use cases for serverless applications include the following:
- Transaction Processing
- Multimedia Transformation and Processing
- Event Streaming
- Software-as-a-service Providers
- Continuous Delivery
- Autoscaling APIs or Websites
If you have questions on how you can best get started on your serverless or cloud-native adoption plans, please engage with us via comments on this blog post, or reach out to us.